There are a lot of useful information on the Internet. How can we automatically get those information? – Yes, Web Crawler.
This post shows how to make a simple Web crawler prototype using Java. Making a Web crawler is not as difficult as it sounds. Just follow the guide and you will quickly get there in 1 hour or less, and then enjoy the huge amount of information that it can get for you. As this is only a prototype, you need spend more time to customize it for your needs.
The following are prerequisites for this tutorial:
- Basic Java programming
- A little bit about SQL and MySQL Database.
If you don’t want to use a database, you can use a file to track the crawling history.
1. The goal
In this tutorial, the goal is as the following:
Given a school root URL, e.g., “mit.edu”, return all pages that contains a string “research” from this school
A typical crawler works in the following steps:
- Parse the root web page (“mit.edu”), and get all links from this page. To access each URL and parse HTML page, I will use JSoup which is a convenient web page parser written in Java.
- Using the URLs that retrieved from step 1, and parse those URLs
- When doing the above steps, we need to track which page has been processed before, so that each web page only get processed once. This is the reason why we need a database.
2. Set up MySQL database
If you are using Ubuntu, you can following this guide to install Apache, MySQL, PHP, and phpMyAdmin.
If you are using Windows, you can simply use WampServer. You can simple download it from wampserver.com and install it in a minute and good to go for next step.
I will use phpMyAdmin to manipulate MySQL database. It is simply a GUI interface for using MySQL. It is totally fine if you any other tools or use no GUI tools.
3. Create a database and a table
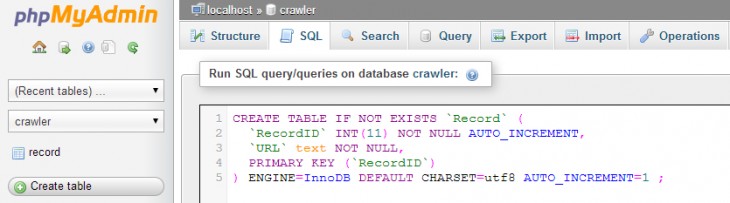
Create a database named “Crawler” and create a table called “Record” like the following:
CREATE TABLE IF NOT EXISTS `Record` ( `RecordID` INT(11) NOT NULL AUTO_INCREMENT, `URL` text NOT NULL, PRIMARY KEY (`RecordID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; |
4. Start crawling using Java
1). Download JSoup core library from http://jsoup.org/download.
Download mysql-connector-java-xxxbin.jar from http://dev.mysql.com/downloads/connector/j/
2). Now Create a project in your eclipse with name “Crawler” and add the JSoup and mysql-connector jar files you downloaded to Java Build Path. (right click the project –> select “Build Path” –> “Configure Build Path” –> click “Libraries” tab –> click “Add External JARs”)
3). Create a class named “DB” which is used for handling database actions.
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public class DB { public Connection conn = null; public DB() { try { Class.forName("com.mysql.jdbc.Driver"); String url = "jdbc:mysql://localhost:3306/Crawler"; conn = DriverManager.getConnection(url, "root", "admin213"); System.out.println("conn built"); } catch (SQLException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } public ResultSet runSql(String sql) throws SQLException { Statement sta = conn.createStatement(); return sta.executeQuery(sql); } public boolean runSql2(String sql) throws SQLException { Statement sta = conn.createStatement(); return sta.execute(sql); } @Override protected void finalize() throws Throwable { if (conn != null || !conn.isClosed()) { conn.close(); } } } |
4). Create a class with name “Main” which will be our crawler.
import java.io.IOException; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Main { public static DB db = new DB(); public static void main(String[] args) throws SQLException, IOException { db.runSql2("TRUNCATE Record;"); processPage("http://www.mit.edu"); } public static void processPage(String URL) throws SQLException, IOException{ //check if the given URL is already in database String sql = "select * from Record where URL = '"+URL+"'"; ResultSet rs = db.runSql(sql); if(rs.next()){ }else{ //store the URL to database to avoid parsing again sql = "INSERT INTO `Crawler`.`Record` " + "(`URL`) VALUES " + "(?);"; PreparedStatement stmt = db.conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS); stmt.setString(1, URL); stmt.execute(); //get useful information Document doc = Jsoup.connect("http://www.mit.edu/").get(); if(doc.text().contains("research")){ System.out.println(URL); } //get all links and recursively call the processPage method Elements questions = doc.select("a[href]"); for(Element link: questions){ if(link.attr("href").contains("mit.edu")) processPage(link.attr("abs:href")); } } } } |
Now you have your own Web crawler. Of course, you will need to filter some links you don’t want to crawl.
The output is the following when I run the code on May 26 2014.
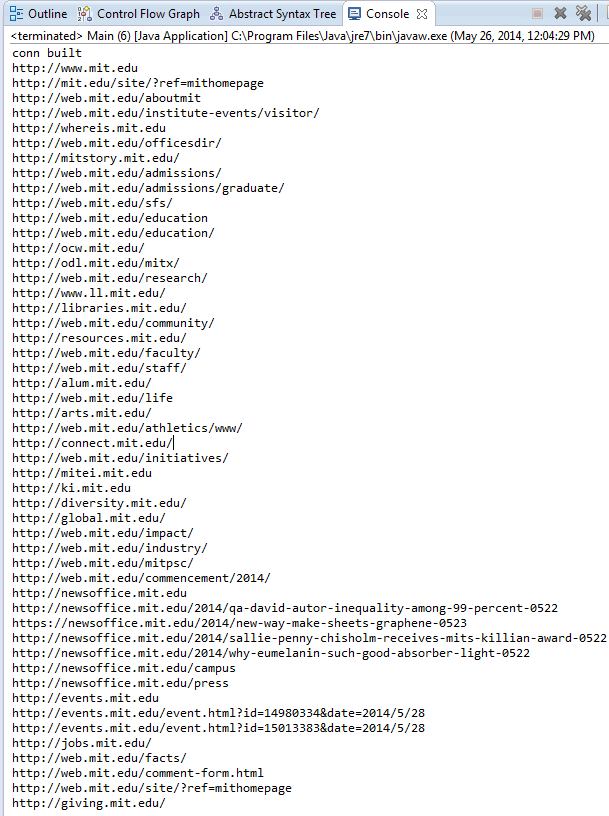
Links:
Java Crawler Source Code Download
Java Crawler on GitHub
http://infinitycarwash.in/
THIS IS NOT WEB CRAWLING…..THIS IS WEB SCRAPING
Thanks for the info. We used this tool for our website http://infinitycarwash.in. It is good codes to use
Thanks For posting web crawler programming . Thanks
Thank you for this simple but yet powerfull crawling app. I was actually learning to develop a crawling program in Python, then I had the ideal to look for the same kind of program in Java. I’m pretty satisfied with your blog post. Awesome work!
Simple web crawler code is here:
http://sunysudan.blogspot.com/2017/06/how-to-make-web-crawler-in-java.html
can someone help me to extract data, in above given example he extract links only
i want to extract research based publication databases..
thank you
its working fine
hey, thanks so much for the upload!
I am just wondering why I can only extract data from mit.edu?
I changed search word from “research” to “people” and used other websites but nothing show up
only mit.edu works. why?
how can i use this program on other websites?
Rather than complicated this with use of DB, u could have simple used some java collection like Set to store traversed URLs. I guess many finding problem here with setting DB connectors.
By the code, if u see from this snippet:
//get all links and recursively call the processPage method
Elements questions = doc.select(“a[href]”);
for(Element link: questions){
if(link.attr(“href”).contains(“mit.edu”))
processPage(link.attr(“abs:href”));
}
Getting all the childs of a node , and inside loop recursively calling one of its child. It means it will go deep first in the tree. SO it is DFS
Sir which search technologie used in this program mean like (bfs ,dfs ) which one is used
Yes, I found it useful.
Add mysql-connector-java-5.1.23-bin.jar in your lib folder
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.sayar.home.wiki.search.db.DatabaseManager.(DatabaseManager.java:15)
at com.sayar.home.wiki.search.crawler.Main.(Main.java:15)
Exception in thread “main” java.lang.NullPointerException
at com.sayar.home.wiki.search.db.DatabaseManager.runSql2(DatabaseManager.java:32)
at com.sayar.home.wiki.search.crawler.Main.main(Main.java:18)
Why i am having this error while compiling the program.Please help me .
I want the content of that url..How does it works.
eg:contact details name
address
number..
can you help me out?
I am getting this error how to resolve it?????????
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Unknown Source)
at DB.(DB.java:13)
at Main.(Main.java:13)
Exception in thread “main” java.lang.NullPointerException
at DB.runSql2(DB.java:30)
at Main.main(Main.java:16)
I copied the exact same code but I am getting only the links present in http://www.mit.edu/ . It’s not returning all pages that contains a string “research” ..Please help ..
i could run your program successfully but when i change the URL it gives my error of unknown host exception can you help?
also how should one get desired data from URL in my case i’m looking for product name and its price in a excel
thank u very much really very helpfull
how do I extract and store images and emails from a webpage to my database….
I have looked through the web but was not able to get a solution….please help
Hi!
Thanks for the help
I am able to write data to file but it shows “ClassNotFoundException” when trying to use daatabase.
Ho do I solve that issue.
I searched the net but did not got any satisfactory solutions
Please help.
can we use this program to crawl multiple websites? and not just one(www.mitedu.com)?
Hello Taylor,
Can you please elaborate this?
TO all those guys who are having this error, It is a database related error which states that the connection to the database was not successful due to the incorrect parameters you supplied to make a connection i.e.
url="jdbc:mysql://localhost:3306/DatabaseName";
String user = "WhateverYourUserNameIs", password = "WhateverYourPasswordis";
Connection conn = DriverManager.getConnection(url,user,password);
I cannot crawl any other webpages other than http://www.mit.edu
Exception in thread “main” java.lang.IllegalArgumentException: usage: supply url to fetch
at org.jsoup.helper.Validate.isTrue(Validate.java:45)
at org.jsoup.examples.ListLinks.main(ListLinks.java:16)
Check your password for connecting with your database.
The default password in wampserver is blank “”.
error: cannot find symbol
public static DB db = new DB();
Hi Iam also getting the same error. I have installed WAMP, but no clue how to create records in it
Console isn’t displaying anything when I run it… but I’m not getting any error messages either. Anyone know what’s going on?
whenever i am running the code, an error message is showing “java.sql.SQLException: Access denied for user ‘root’@’localhost’ (using password: YES)”….tell me what to do next
Changed to
Document doc = Jsoup.connect(URL).timeout(0).get();
still getting :
Exception in thread “main” java.lang.IllegalArgumentException: usage: java -cp jsoup.jar org.jsoup.examples.HtmlToPlainText url [selector]
at org.jsoup.helper.Validate.isTrue(Validate.java:45)
at org.jsoup.examples.HtmlToPlainText.main(HtmlToPlainText.java:35)
Changed to
Document doc = Jsoup.connect(URL).timeout(0).get();
still getting :
Exception in thread “main” java.lang.IllegalArgumentException: usage: java -cp jsoup.jar org.jsoup.examples.HtmlToPlainText url [selector]
at org.jsoup.helper.Validate.isTrue(Validate.java:45)
at org.jsoup.examples.HtmlToPlainText.main(HtmlToPlainText.java:35)
Hey, nice post. It’s worth mentioning in crawling you should parse the domain’s robots.txt first and create a URL exclusion set to make sure you don’t anger any webmasters 😉
Hi, Im new to making web crawlers and am doing so for the final project in my class. I want my web crawler to take in an address from a user and plug into maps.google.com and then take the route time and length to use in calculations. How do I adapt the crawler you provided to do that? Or if not possilbe, how do I write a crawler that can do that operation?
It worked!!
THANX ALOT!!
Hi,
Thanks for this wonderful code that you have put up! Makes writing the first crawler very very easy!
😀
Well, the problem that I am currently facing is that I am not sure of how to distinguish between a page that has an article like: http://tech.firstpost.com/news-analysis/new-twist-trai-says-war-between-telco-media-house-caused-net-neutrality-debate-263618.html and a page that has many links to other articles like: http://tech.firstpost.com/.
Is there some meta tag or some other mechanism that exists to distinguish between these two types of pages?
I also want to filter out pages that photos, slideshows, links to social media accounts, etc. Other than checking for words like ‘photo’,’gallery’,’slidehow’,’plus.google.com’ in the URL is there any way of filtering these out using some smarter jsoup(any other api) utilities?
After inserting 46 rows, it refuses to insert any more in the database. How to insert the rest of the links?
Also, using a database for tracking is a bit over-engineered since it is cleared on startup. However, it will come in handy if you want to track which pages has been crawled if you stop the process and want to continue later on.
Doesn’t really crawl as it is the same page that is fetched every time. Use:
Document doc = Jsoup.connect(URL).get();
For those new to this, here are some tips:
1) To add jar files, right click the project name->properties->Java Build Path->Add External Jars…
2) I had to add mysql-connector jar file as well
3) change the username/password (I’m not sure what it is) from “admin213” to “”. This means the line should be >conn = DriverManager.getConnection(url, “root”,””);
Thanks it was a very good starting point….
Im getting this sort of an error on running my java code. Any ideas?
Access denied for user ‘root’@’localhost’ (using password: YES)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1073)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4096)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:4028)
at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:951)
at com.mysql.jdbc.MysqlIO.proceedHandshakeWithPluggableAuthentication(MysqlIO.java:1717)
at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1276)
at com.mysql.jdbc.ConnectionImpl.coreConnect(ConnectionImpl.java:2395)
at com.mysql.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:2428)
at com.mysql.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:2213)
at com.mysql.jdbc.ConnectionImpl.(ConnectionImpl.java:797)
at com.mysql.jdbc.JDBC4Connection.(JDBC4Connection.java:47)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:389)
at com.mysql.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:305)
at java.sql.DriverManager.getConnection(Unknown Source)
at java.sql.DriverManager.getConnection(Unknown Source)
at DB.(DB.java:11)
at Main.(Main.java:13)
Exception in thread “main” java.lang.NullPointerException
at DB.runSql2(DB.java:26)
at Main.main(Main.java:16)
We can use selenium to crawl a website.
See below code. It will open firefox window and will crawl a website.
I think this is the simplest way to do it.
Hope this will help to all of you.
Thanks.
– Mehul Popat
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
public class SimpleCrawler {
public static void main(String[] args) {
WebDriver wd = new FirefoxDriver();
wd.get(“http://www.mit.edu”);
List allLinks = wd.findElements(By.tagName(“a”));
for(int i = 0 ; i< allLinks.size() ; i++)
{
if(allLinks.get(i).getAttribute("href").contains("mit.edu"))
{
System.out.println(allLinks.get(i).getAttribute("href"));
}
}
wd.close();
}
}
We can use selenium to crawl a website.
See below code. It will open firefox window and will crawl a website.
I think this is the simplest way to do it.
Hope this will help to all of you.
Thanks.
– Mehul Popat
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
public class SimpleCrawler {
public static void main(String[] args) {
WebDriver wd = new FirefoxDriver();
wd.get(“http://www.mit.edu”);
List allLinks = wd.findElements(By.tagName(“a”));
for(int i = 0 ; i< allLinks.size() ; i++)
{
if(allLinks.get(i).getAttribute("href").contains("mit.edu"))
{
System.out.println(allLinks.get(i).getAttribute("href"));
}
}
wd.close();
}
}
I’m pretty sure you had to check the link ‘URL’ for the string “research”, instead of hard coding “www.mit.edu” for each recursive call. Good job on the crawler though
I’m getting an error “java.net.ConnectException: Connection timed out: connect”.
I recently placed a “timeout(0)” before .get() on the Document. Is there any other solutions for this? My firewalls are completely shut off.
It should be db.runSql2(“TRUNCATE Record;”); since you are making changes in the table. Use executeQuery() only if you’re just getting data from the table. 🙂
Do you have a java to mysql connector?
I do not get a response from the server, cause by line: Statement sta = conn.createStatement(); (NullPointer Exception). Does anyone know what the problem might be?
Eclipse says I do not get a response from the server…
I get a NullPointerException for the line: Statement sta = conn.createStatement();
Does anyone know what to do?
Hey it works for me except the “db.runSql(“TRUNCATE Record;”);” I keep getting the error “Exception in thread “main” java.sql.SQLException: Can not issue data manipulation statements with executeQuery().” When I comment out the line, everything works great?
This line might have a bug.
if(link.attr(“href”).contains(“mit.edu”))
I think it should have abs: in it so that relative URLs are changed to include the domain.
`if(link.attr(“abs:href”).contains(“mit.edu”))`
If I want to crawl to the specific keyword inside the webpage. how can i do that? can u please help me out on this one?
I can never find a java source that shows a proper crawler. All of these limited to domain specific things. Would be cool if someone did a writeup of an actual commercial style crawler ( kind of the point of a crawler ) because there are already a thousand simple programss for small range collection.
Jsoup.connect(URL).ignoreContentType(true).get();
Hi, I am in the mySQL database guide under step 2 and trying to create my new site in Apache2 (under Virtual Hosts). After I run the command gksudo gedit /etc/apache2/sites-available/mysite.conf and access the file, I can’t find the Directory directive to complete step 4. When I don’t follow his step, http://localhost doesn’t work, giving me the error that “I Don’t have access to this page.” Help!
If you are using Wampm I’m pretty sure you did not get rid of the password field mentioned in the DB class.
It should something like this ” conn = DriverManager.getConnection(url, “root”, “”);”
Wang, Thanks. I tried the code and I am now search all the pages I want and getting my results per keyword i choose. This is very good and appreciate your gesture in schooling us.
Netbeans’s console displays nothing !!!
This is amazing and so easy to implement. Thanks for sharing you knowledge.
Nice!
Exception in thread “main” java.lang.NullPointerException in following lines
Statement sta = conn.createStatement();
db.runSql2(“TRUNCATE Record;”);
I think some part with reference link is ok, but the whole page of the content is not.
Thanks nice tutorial.
I had one question, if I use web Crawler and showing that data or information in my own site. Is it legal or we need to take permission to those URL owner.
Thanks
Getting following exception when trying to get link to a pdf file
org.jsoup.UnsupportedMimeTypeException: Unhandled content type. Must be text/*, application/xml, or application/xhtml+xml. Mimetype=application/pdf, URL=http://www.xyz.com/files/.pdf
Any suggestions?
hey thanx a lot bro… i use to think that making a crawler is a big deal u know.. but never new it is that easy..
it took me a couple of minutes to understand .. u made my life a lot easy …thanx n god bless.. cheers!!
lolll!!! ^^
sql = “INSERT INTO `Crawler`.`Record` ” + “(`URL`) VALUES ” + “(?);”;
This INSERTS the crawled url into the “Record” TABLE belonging to the DATABASE called “Crawler”
how to run this programme? t shows error 404 is not found
Tumhari aisi taisi…lab k andar harkatein mat pela karo
Muahahahahahah!
This is my lab assignment! Copy-Paste it!
Hi. I want to thank you for this guide! It’s been really helpfull! Only one question:
Could you tell me what does this code exactly mean?
sql = “INSERT INTO `Crawler`.`Record` ” + “(`URL`) VALUES ” + “(?);”;
Because my aim was to add the entire sourcecode of each page taken by the result of the .get() into my database, and not only the URL. I’ve already made a new column called Source where i want to save it, but i can’t find the right query.
Thank you very much!
I changed throws Exception insted of IOException. It is OK in my case
public static void main(String[] args) throws SQLException, Exception {
db.runSql2(“TRUNCATE Record;”);
processPage(“http://www.beatcourse.com”);
how can I download all images from this site by java
http://gaga.vn
if i am using DB2 then what i have to write in place of
ResultSet runSql(String sql) and public boolean runSql2(String sql)methods
When I run Main, it only shows the “conn built”, And I see that in the Record Table stores all URLs inside the HTML page when I open it from PHPMyAdmin. But nothing more is shown in the console.
I tryed changin PhD for other word.
And something strange is, when I ran few more times, it keeps displaying all the URL (with no filter) in console. Don’t no why it doesn’t do anymore that. Now I try and it only does what I said at beginig.
Thank you for this :), but you are only processing the links on the first URL http://www.mit.edu/. Because in the Jsoup.connect, it should be Jsoup.connect(URL) instead of Jsoup.connect(http://www.mit.edu/).
import org.jsoup.Jsoup; proide link for this api
wezxcxzczxczxc
thank you…
I m working on project to develop a web crawler for YouTube.
.so can u help me? ? or give some ideas.
plz try Jsoup.connect(“url”).timeout(0).get()
https://www.udemy.com/building-a-search-engine/ this tutorial explains everything
Jsoup.connect(“http://www.udel.edu/”).get();
This line is throwing an exception, could you tell me why? and how to handle it