Case Study
Image you have a blog which contains a lot of nice articles. You put ads at the top of each article and hope to gain some revenue. After a while and from your report, you see that some posts generate revenue and some do not. Assuming that whether an article generates revenue or not depends on how many pictures and text paragraphs in it.
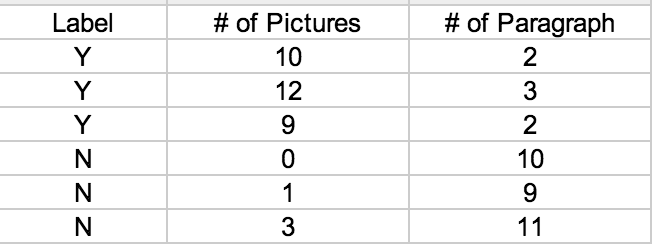
Given the dataset:
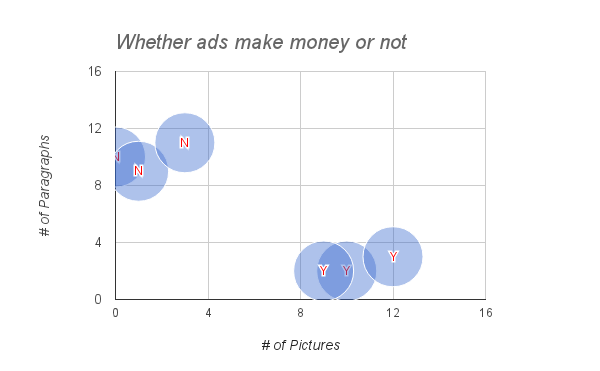
we can plot them in the figure below.
How K-Nearest Neighbors (KNN) algorithm works?
When a new article is written, we don’t have its data from report. If we want to know whether the new article can generate revenue, we can 1) computer the distances between the new article and each of the 6 existing articles, 2) sort the distances in descending order, 3) take the majority vote of k. This is the basic idea of KNN.
Now let’s guess a new article, which contains 13 pictures and 1 paragraph, can make revenue or not. By visualizing this point in the figure, we can guess it will make profit. But we will do it in Java.
Java Solution
kNN is also provided by Weka as a class “IBk”. IBk implements kNN. It uses normalized distances for all attributes so that attributes on different scales have the same impact on the distance function. It may return more than k neighbors if there are ties in the distance. Neighbors are voted to form the final classification.
First prepare your data by creating a txt file “ads.txt”:
@relation ads
@attribute pictures numeric
@attribute paragraphs numeric
@attribute profit {Y, N}
@data
10,2,Y
12,3,Y
9,2,Y
0,10,N
1,9,N
3,11,N
Java Code:
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import weka.classifiers.Classifier; import weka.classifiers.lazy.IBk; import weka.core.Instance; import weka.core.Instances; public class KNN { public static BufferedReader readDataFile(String filename) { BufferedReader inputReader = null; try { inputReader = new BufferedReader(new FileReader(filename)); } catch (FileNotFoundException ex) { System.err.println("File not found: " + filename); } return inputReader; } public static void main(String[] args) throws Exception { BufferedReader datafile = readDataFile("ads.txt"); Instances data = new Instances(datafile); data.setClassIndex(data.numAttributes() - 1); //do not use first and second Instance first = data.instance(0); Instance second = data.instance(1); data.delete(0); data.delete(1); Classifier ibk = new IBk(); ibk.buildClassifier(data); double class1 = ibk.classifyInstance(first); double class2 = ibk.classifyInstance(second); System.out.println("first: " + class1 + "\nsecond: " + class2); } } |
Output:
first: 0.0 second: 1.0
References:
1. http://weka.sourceforge.net/doc.dev/weka/classifiers/lazy/IBk.html
2. http://www.cc.uah.es/drg/courses/datamining/IntroWeka.pdf
I think that you get result 0.0 for Y=>YES and 1.0 for N=>NO.
I think it is because this definition in the file ads.txt:
@attribute profit {Y, N}
Y is on the 0 index and N is on the 1 index.
what if i got input and get its nearest neighbor what should i do ???
first: 0.0
second: 0.0
is thec correct output.
When you try to classify 4,5 or 6th instance you get 1.0 as output
actualy please tell me what is the actual process behind this . and how we get this output?
When running this example I get output 0.0 for both first and second, what’s the deal with that? Also, like Juan, it would be interesting to know exactly what the output means.
THIS IS NOT WHAT PEOPLE LOOK FOR!
What does the output exactly mean? Is it related to the revenue of the new article?