You may often need a counter to understand the frequency of something (e.g., words) from a database or text file. A counter can be easily implemented by using a HashMap in Java. This article compares different approaches to implement a counter. Finally, an efficient one will be concluded.
UPDATE: Check out Java 8 counter, writing a counter is just 2 simple lines now.
1. The Naive Counter
Naively, it can be implemented as the following:
String s = "one two three two three three"; String[] sArr = s.split(" "); //naive approach HashMap<String, Integer> counter = new HashMap<String, Integer>(); for (String a : sArr) { if (counter.containsKey(a)) { int oldValue = counter.get(a); counter.put(a, oldValue + 1); } else { counter.put(a, 1); } } |
In each loop, you check if the key exists or not. If it does, increment the old value by 1, if not, set it to 1. This approach is simple and straightforward, but it is not the most efficient approach. This method is considered less efficient for the following reasons:
- containsKey(), get() are called twice when a key already exists. That means searching the map twice.
- Since Integer is immutable, each loop will create a new one for increment the old value
2. The Better Counter
Naturally we want a mutable integer to avoid creating many Integer objects. A mutable integer class can be defined as follows:
class MutableInteger { private int val; public MutableInteger(int val) { this.val = val; } public int get() { return val; } public void set(int val) { this.val = val; } //used to print value convinently public String toString(){ return Integer.toString(val); } } |
And the counter is improved and changed to the following:
HashMap<String, MutableInteger> newCounter = new HashMap<String, MutableInteger>(); for (String a : sArr) { if (newCounter.containsKey(a)) { MutableInteger oldValue = newCounter.get(a); oldValue.set(oldValue.get() + 1); } else { newCounter.put(a, new MutableInteger(1)); } } |
This seems better because it does not require creating many Integer objects any longer. However, the search is still twice in each loop if a key exists.
3. The Efficient Counter
The HashMap.put(key, value) method returns the key’s current value. This is useful, because we can use the reference of the old value to update the value without searching one more time!
HashMap<String, MutableInteger> efficientCounter = new HashMap<String, MutableInteger>(); for (String a : sArr) { MutableInteger initValue = new MutableInteger(1); MutableInteger oldValue = efficientCounter.put(a, initValue); if(oldValue != null){ initValue.set(oldValue.get() + 1); } } |
4. Performance Difference
To test the performance of the three different approaches, the following code is used. The performance test is on 1 million times. The raw results are as follows:
Naive Approach : 222796000 Better Approach: 117283000 Efficient Approach: 96374000
The difference is significant – 223 vs. 117 vs. 96. There is huge difference between Naive and Better, which indicates that creating objects are expensive!
String s = "one two three two three three"; String[] sArr = s.split(" "); long startTime = 0; long endTime = 0; long duration = 0; // naive approach startTime = System.nanoTime(); HashMap<String, Integer> counter = new HashMap<String, Integer>(); for (int i = 0; i < 1000000; i++) for (String a : sArr) { if (counter.containsKey(a)) { int oldValue = counter.get(a); counter.put(a, oldValue + 1); } else { counter.put(a, 1); } } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("Naive Approach : " + duration); // better approach startTime = System.nanoTime(); HashMap<String, MutableInteger> newCounter = new HashMap<String, MutableInteger>(); for (int i = 0; i < 1000000; i++) for (String a : sArr) { if (newCounter.containsKey(a)) { MutableInteger oldValue = newCounter.get(a); oldValue.set(oldValue.get() + 1); } else { newCounter.put(a, new MutableInteger(1)); } } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("Better Approach: " + duration); // efficient approach startTime = System.nanoTime(); HashMap<String, MutableInteger> efficientCounter = new HashMap<String, MutableInteger>(); for (int i = 0; i < 1000000; i++) for (String a : sArr) { MutableInteger initValue = new MutableInteger(1); MutableInteger oldValue = efficientCounter.put(a, initValue); if (oldValue != null) { initValue.set(oldValue.get() + 1); } } endTime = System.nanoTime(); duration = endTime - startTime; System.out.println("Efficient Approach: " + duration); |
When you use a counter, you probably also need a function to sort the map by value. You can check out the frequently used method of HashMap.
5. Solutions from Keith
Added a couple tests:
1) Refactored “better approach” to just call get instead of containsKey. Usually, the elements you want are in the HashMap so that reduces from two searches to one.
2) Added a test with AtomicInteger, which michal mentioned.
3) Compared to singleton int array, which uses less memory according to http://amzn.com/0748614079
I ran the test program 3x and took the min to remove variance from other programs. Note that you can’t do this within the program or the results are affected too much, probably due to gc.
Naive: 201716122 Better Approach: 112259166 Efficient Approach: 93066471 Better Approach (without containsKey): 69578496 Better Approach (without containsKey, with AtomicInteger): 94313287 Better Approach (without containsKey, with int[]): 65877234
Better Approach (without containsKey):
HashMap<String, MutableInteger> efficientCounter2 = new HashMap<String, MutableInteger>(); for (int i = 0; i < NUM_ITERATIONS; i++) { for (String a : sArr) { MutableInteger value = efficientCounter2.get(a); if (value != null) { value.set(value.get() + 1); } else { efficientCounter2.put(a, new MutableInteger(1)); } } } |
Better Approach (without containsKey, with AtomicInteger):
HashMap<String, AtomicInteger> atomicCounter = new HashMap<String, AtomicInteger>(); for (int i = 0; i < NUM_ITERATIONS; i++) { for (String a : sArr) { AtomicInteger value = atomicCounter.get(a); if (value != null) { value.incrementAndGet(); } else { atomicCounter.put(a, new AtomicInteger(1)); } } } |
Better Approach (without containsKey, with int[]):
HashMap<String, int[]> intCounter = new HashMap<String, int[]>(); for (int i = 0; i < NUM_ITERATIONS; i++) { for (String a : sArr) { int[] valueWrapper = intCounter.get(a); if (valueWrapper == null) { intCounter.put(a, new int[] { 1 }); } else { valueWrapper[0]++; } } } |
Guava’s MultiSet is probably faster still.
6. Conclusion
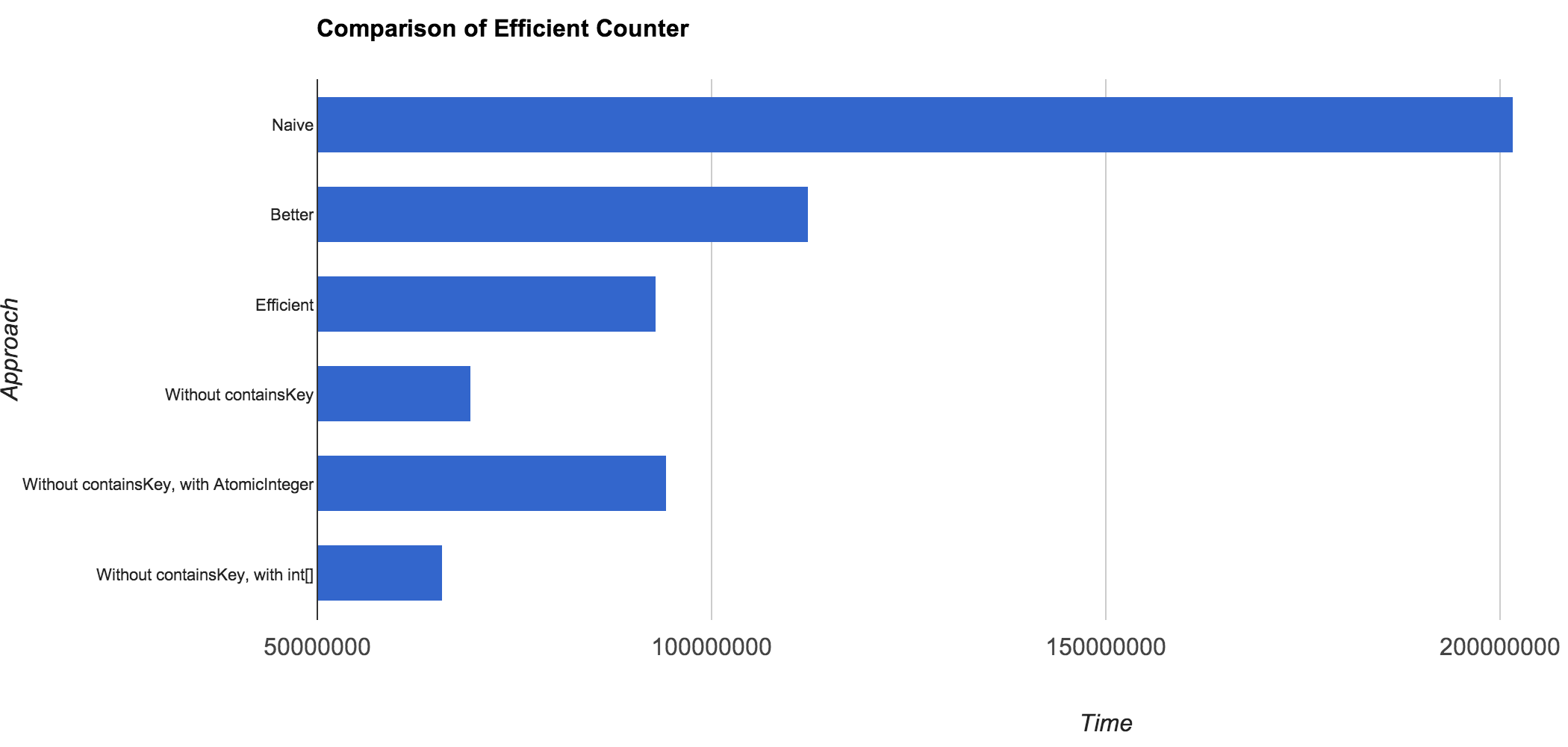
The winner is the last one which uses int arrays.
References:
1. Most efficient way to increment a Map value in Java.
2. HashMap.put()
I have gotten the result as following.
Naive Approach : 435421694
Better Approach: 253065119
Efficient Approach: 773357144
I have gotten the result as following.
Naive Approach : 435421694
Better Approach: 253065119
Efficient Approach: 773357144
great!
what is the significance of : for (int i = 0; i < 1000000; i++) in approach 4 ??
// efficient approach with int
startTime = System.currentTimeMillis();
HashMap intCounter = new HashMap();
for (int i = 0; i 0) {
intCounter.put(a, 1);
} else {
valueWrapper++;
}
}
endTime = System.currentTimeMillis();
duration = endTime – startTime;
System.out.println(“Efficient Approach with int: ” + duration);
Naive Approach : 3087
Better Approach: 1361
Efficient Approach: 1476
Efficient Approach with int[]: 893
Efficient Approach with int: 316
Efficient Approach: 93066471
Better Approach (without containsKey): 69578496
I am curious why above two cases make much difference? I expect both should be around same order of time. Any explanation?
Thanks.
very impressive
I’d look into http://docs.guava-libraries.googlecode.com/git/javadoc/com/google/common/util/concurrent/AtomicLongMap.html as well
Using an array is the most efficient solution so far.
good job,i like ….
Added a couple tests:
1) Refactored “better approach” to just call get instead of containsKey. Usually, the elements you want are in the HashMap so that reduces from two searches to one.
2) Added a test with AtomicInteger, which michal mentioned.
3) Compared to singleton int array, which uses less memory according to http://amzn.com/0748614079
I ran the test program 3x and took the min to remove variance from other programs. Note that you can’t do this within the program or the results are affected too much, probably due to gc.
Naive: 201716122
Better Approach: 112259166
Efficient Approach: 93066471
Better Approach (without containsKey): 69578496
Better Approach (without containsKey, with AtomicInteger): 94313287
Better Approach (without containsKey, with int[]): 65877234
Better Approach (without containsKey):
HashMap efficientCounter2 = new HashMap();
for (int i = 0; i < NUM_ITERATIONS; i++)
for (String a : sArr) {
MutableInteger value = efficientCounter2.get(a);
if (value != null) {
value.set(value.get() + 1);
}
else {
efficientCounter2.put(a, new MutableInteger(1));
}
}
Better Approach (without containsKey, with AtomicInteger):
HashMap atomicCounter = new HashMap();
for (int i = 0; i < NUM_ITERATIONS; i++)
for (String a : sArr) {
AtomicInteger value = atomicCounter.get(a);
if (value != null) {
value.incrementAndGet();
}
else {
atomicCounter.put(a, new AtomicInteger(1));
}
}
Better Approach (without containsKey, with int[]):
HashMap intCounter = new HashMap();
for (int i = 0; i < NUM_ITERATIONS; i++)
for (String a : sArr) {
int[] valueWrapper = intCounter.get(a);
if (valueWrapper == null) {
intCounter.put(a, new int[] { 1 });
}
else {
valueWrapper[0]++;
}
}
Guava's MultiSet is probably faster still.
wow.. I never knew about MultiSet… Thanks for this…
good:
http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ConcurrentHashMap.html,
http://docs.oracle.com/javase/7/docs/api/java/util/concurrent/atomic/AtomicInteger.html
(putIfAbsent, incrementAndGet)
better:
http://docs.guava-libraries.googlecode.com/git/javadoc/com/google/common/collect/Multiset.html
(add)
why not:
for (String a : sArr) {
MutableInteger oldValue = ncounter.get(a);
if (oldValue == null)
ncounter.put(a, new MutableInteger(1));
else
oldValue.set(oldValue.get()+1);
}
Is HashMap thread safety? Maybe ConcurrentHashMap should be used for the counter case.