Recurrent Neural Networks (RNNs) are gaining a lot of attention in recent years because it has shown great promise in many natural language processing tasks. Despite their popularity, there are a limited number of tutorials which explain how to implement a simple and interesting application using the state-of-art tools. In this series, we will use a recurrent neural network to train an AI programmer, which can write Java code like a real programmer (hopefully). The following will be covered:
1. Building a simple AI programmer (this post)
2. Improving the AI programmer – Using tokens
3. Improving the AI programmer – Using different network structures
This post shows the steps to construct an LSTM neural network and use it to generate Java code. If you follow the post, running the code is just one click away. (But as the first step, you will need to set up the development environment for deep learning. You can follow this post (http://www.programcreek.com/2017/01/set-up-development-environment-for-deep-learning/) which shows the best and simplest way to set up the working environment.
The goal of this series is providing an entry point for deep learning. Building a deep learning model is like painting an oil painting. You can keep improving the model as soon as you start and get your first model working.
1. Getting the training raw data
I’m using the source code of JDK as the training data. It is available here. We are building a sequence-to-sequence prediction model and the input sequence is character sequence. Each .java file is scanned and aggregated into one file called “jdk-chars.txt”. In addition, comments are ignored, because we want the AI programmer to learn how to code. Comments make the data noisy. (check out this post to see how to remove comments.) For your convenience, the aggregated file is included in the GitHub repository of this project. You can find the link at the end of this post.
The following code reads the jdk-chars.txt and slice it to fit the hardware capability of my desktop. In my case, I only used 20% of the code as shown in the code.
path = "./jdk-chars.txt" text = open(path).read() slice = len(text)/5 slice = int(slice) # slice the text to make training faster text = text[:slice] print('# of characters in file:', len(text)) |
2. Building index to address the characters
LSTM inputs can only understand numbers, so first we need to assign a unique integer to each character.
For example, if there are 65 unique characters in the code, we assign a number to each of the 65 characters. The code below builds a dictionary with the entries like [ “{†: 0 ] [ “a†: 1 ], … ]. The reversed dictionary is also generated for decoding the output of LSTM.
chars = sorted(list(set(text))) print('# of unique chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) |
3. Preparing the training sequences with labels
Next, we need to prepared training data with labels. An X is a sequence with a specific length we define (40 in my case) and y is the next character of the sequence.
For example, from the following line:
int weekOfYear = isSet(WEEK_OF_YEAR) ? field[MAX_FIELD + WEEK_OF_YEAR] : 1; ... ...
A sample of X is
int weekOfYear = isSet(WEEK_OF_YEAR) ? fi
and the y is the next character
e
Here we cut the text in redundant sequences of 40 characters.
NUM_INPUT_CHARS = 40 STEP = 3 sequences = [] next_chars = [] for i in range(0, len(text) - NUM_INPUT_CHARS, STEP): sequences.append(text[i: i + NUM_INPUT_CHARS]) next_chars.append(text[i + NUM_INPUT_CHARS]) print('# of training samples:', len(sequences)) |
We are trying to build a network with a structure like this:
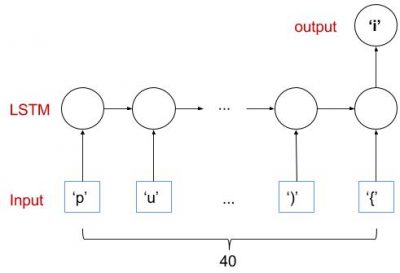
4. Vectorizing training data
Once the training data is prepared, it needs to be converted to vectors. As we have prepared char_indices and indices_char in the second step, the following code can easily convert our training data to vectors with one-hot encoding. For example, the character with index 11 would be the vector of all 0’s and a 1 at position 11.
print('Vectorize training data') X = np.zeros((len(sequences), NUM_INPUT_CHARS, len(chars)), dtype=np.bool) y = np.zeros((len(sequences), len(chars)), dtype=np.bool) for i, sequence in enumerate(sequences): for t, char in enumerate(sequence): X[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 |
5. Constructing a single layer LSTM model
The following code defines the structure of the neural network. The network contains a layer of LSTM with 128 hidden units. The input_shape parameter specifies the input sequence length (NUM_INPUT_CHARS) and the dimension of input at each time (i.e., size of unique characters).
print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(NUM_INPUT_CHARS, len(chars)))) model.add(Dense(len(chars))) model.add(Activation('softmax')) optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) print(model.summary()) |
The final Dense() layer is meant to be an output layer with softmax activation, allowing for len(chars) -way classification of the input vectors. During training, back-propagation-through-time starts at the output layer, so it serves an important purpose with the chosen optimizer=rmsprop. LSTM is note meant to be an output layer in Keras.
Optimizer is the optimization function. If you do not know this term, you may be familiar with the commonly used optimization function in logistic regression – stochastic gradient descent. It is a similar thing.
The last line specifies the cost function. In this case, we use ‘categorical_crossentropy’. You may check out this nice post to understand why crossentropy is better than mean squared error (MSE) in this case.
6. Training model and generating Java code
The sample function is used to sample an index from a probability array. For example, given preds=[0.5,0.2,0.3] and a default temperature, the function would return index 0 with probability 0.5, 1 with probability 0.2, or 2 with probability 0.3. It is used to avoid generating the same sequence over and over again. We want to see some different code sequences the AI Programmer can code.
def sample(preds, temperature=1.0): preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) |
# train the model, output generated text after each iteration for iteration in range(1, 60): print() print('-' * 50) print('Iteration', iteration) model.fit(X, y, batch_size=128, epochs=1) start_index = random.randint(0, len(text) - NUM_INPUT_CHARS - 1) for diversity in [0.2, 0.5, 1.0, 1.2]: print() print('----- diversity:', diversity) generated = '' sequence = text[start_index: start_index + NUM_INPUT_CHARS] generated += sequence print('----- Generating with seed: "' + sequence + '"') sys.stdout.write(generated) for i in range(400): x = np.zeros((1, NUM_INPUT_CHARS, len(chars))) for t, char in enumerate(sequence): x[0, t, char_indices[char]] = 1. preds = model.predict(x, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] generated += next_char sequence = sequence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() |
7. Results
It takes a few hours to train the model. And finally the generated code looks like the following:
----- diversity: 1.2
----- Generating with seed: "eak positions used by next()
// and prev"
eak positions used by next()
// and previos <
als.get[afip(lookupFDataNtIndexPesicies- > = nuls.simys);
} e.apfwn 0;
for;
rerendenus = contaroyCharset() :
Attch ;
margte.adONamel = getScale(); i {
int exponentace = sed, off endexpVal.vilal = 0,
break;
localicIntLullAtper.sudid);
}
void fam();
;
if (offset:
b = t);
if (false;
private byte[] is(-notren} fig ist[(i = 0)
molInd);
if (end < = mame") inie = torindLotingenFiols.INFGNTR_FIELD_(ne
The code generated does not make much sense, not even compile. But we can still see that LSTM captures some words and syntax. For example, "void fam();". You can also take a look at the code generated in the earlier iterations. They make less sense.
If you tune the parameters (such as NUM_INPUT_CHARS and STEP) and train longer, you may get better results. Feel free to try. I was running out of time and wanted to publish this post. More importantly, I know a better way to do this job which is shown in the next post.
8. What's Next?
In this post, I used characters sequences as input to train the model and the model predicts a character sequence. Other than turning the parameters of the basic LSTM neural network, we can also use tokens instead of characters and use different network structures. We will explore those in the next posts.
Source Code
1) The source code of this post is lstm_ai_coder_chars.py which is located at https://github.com/ryanlr/RNN-AI-Programmer
2) The code is modified based on the Keras example lstm_text_generation.py which is available here https://github.com/fchollet/keras/tree/master/examples.
This is really nice as it helped me a lot and definitely it will help others. Thanks for sharing this useful content with the public. If you get a chance then have a look at it- uipath course
Data file is no longer available at the location you pointed to. Can you point to where the data are currently warehoused?
This is such a great resource that you are providing and you give it away I love seeing
“””Dream Teach Provides Best Teaching and Learning resources of geography in UK. It provides info on a geographical environmental quiz, journals that are helpful for Primary & Secondary Schools Teachers and Students.””
To know more about DreamTeach
Visit: geography learning resources!
This is such a great resource that you are providing and you give it away I love seeing
“Abacus Trainer provides the Best Abacus Online Classes for kids. Best platform for Vedic Math Online Training classes from certified teachers for 5 years children.
To know more about AbacusTrainer
Visit: abacus classes online!