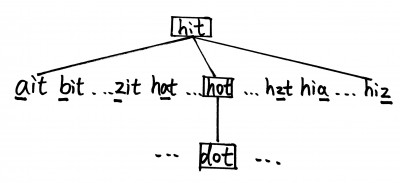
Given two words (start and end), and a dictionary, find the length of shortest transformation sequence from start to end, such that only one letter can be changed at a time and each intermediate word must exist in the dictionary. For example, given:
start = "hit" end = "cog" dict = ["hot","dot","dog","lot","log"]
One shortest transformation is “hit” -> “hot” -> “dot” -> “dog” -> “cog”, the program should return its length 5.
Java Solution
This is a search problem, and breath-first search guarantees the optimal solution.
class WordNode{ String word; int numSteps; public WordNode(String word, int numSteps){ this.word = word; this.numSteps = numSteps; } } public class Solution { public int ladderLength(String beginWord, String endWord, Set<String> wordDict) { LinkedList<WordNode> queue = new LinkedList<WordNode>(); queue.add(new WordNode(beginWord, 1)); wordDict.add(endWord); while(!queue.isEmpty()){ WordNode top = queue.remove(); String word = top.word; if(word.equals(endWord)){ return top.numSteps; } char[] arr = word.toCharArray(); for(int i=0; i<arr.length; i++){ for(char c='a'; c<='z'; c++){ char temp = arr[i]; if(arr[i]!=c){ arr[i]=c; } String newWord = new String(arr); if(wordDict.contains(newWord)){ queue.add(new WordNode(newWord, top.numSteps+1)); wordDict.remove(newWord); } arr[i]=temp; } } } return 0; } } |
Simple Java Solution With Step By Step Explanation .
https://youtu.be/rMveRF-BYac
So my thought, if the dictionary isn’t that big, provide all options of the dictionary words with one letter missing.
This way, we can find the matching “1-letter changed” quickly – without traversing through all the abc.
Such a dictionary from the example would be:
[-ot, h-t, ho-, -ot, d-t, do-, -og, d-g, do-, -ot, l-t, lo-, -og, l-g, lo-].
We still need to save the original word so we’ll add it to the dictionary.
If we have the space, and can partition the dictionary based on string length, the iteration over the abc would be faster – O(size-of-word) instead of O(abc…z)=O(26).
What do you think?
So the solution I see iterates over all the “abc…z” – for each letter in each word in the queue. On each iteration, the new built word is compared to all dictionary words, using
Set.contains().I was thinking, perhaps it might be faster to compare letter by letter.
But the set, especially if it’s a
HashSet, will do the contains much faster because of the String’shashCode().Just sharing a thought 🙂
LOL SERIOUSLY 😀
wow, what a catch man!
breadth not breath ..
const shortestPath = (start, end, dict, path=[]) => {
if (start === end) {
return 2
}
let results = []
for (var i = 0; i < start.length; i++ ) {
for (var j ='a'.charCodeAt(0); j -1 && path.indexOf(next) === -1) {
results.push(shortestPath(next, end, dict, path.concat(next)) + 1)
} else if (next === end) {
return 2
}
}
}
return Math.min(...results)
}
defining distance between words to be number of letters which are different then we start like this
add initial into processing queue
add end to dictionary
dequeuing from processing queue
compute distance from item to each in the dictionary O(Dict)
add to queue the ones with distance one and remove them from dict so that you don’t loop
If the dictionary can be prepressed then you can organize it as a graph with arches connecting elements which have dinstance 1.
Then is just a matter of breath-first search and display the result.
You have to check the newWord with the endWord
String newWord = new String(arr);
if (dict.contains(newWord)) {
System.out.println(newWord);
queue.add(new WordNode(newWord, top.numSteps + 1));
dict.remove(newWord);
// you have to add the next lines.
if (newWord.equals(end)) {
// System.out.println("equals!");
return top.numSteps;
}
}
// “hit” -> “cit” -> “cot” -> “cog” => every intermediate word must exist in the dictionary, but “cit” doesn’t.
Uhhh… It’s breadth-first search
I have Solved this problem in my way.Can please anyone locate the use case in which it will break
package com.cpa.examples;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
public class WordLadder {
private static String start = “hit”;
private static String end = “cog”;
private static List Dictionary = null;
private static ArrayList availablePathCntList = new ArrayList();
public static void main(String[] args) {
Dictionary = new ArrayList();
Dictionary.add(“hot”);
Dictionary.add(“dot”);
Dictionary.add(“dog”);
Dictionary.add(“lot”);
Dictionary.add(“log”);
Dictionary.add(“cog”);
HashSet used = new HashSet();
used.add(start);
int count = 0;
find(Dictionary, start, end, used, count);
System.out.println(availablePathCntList);
}
private static int find(List dictionary, String start, String end, HashSet used, int count) {
if (start == end) {
availablePathCntList.add(count);
return 0;
}
if (difference(start, end) == 1) {
availablePathCntList.add(count + 1);
return 0;
}
for (String word : dictionary) {
int diff = difference(start, word);
if (difference(end, word) == 0) {
availablePathCntList.add(1);
continue;
}
if (diff == 0) {
availablePathCntList.add(count);
continue;
}
if (diff <= 1 && used.add(word)) {
System.out.println("Your word is: " + start + " and matching word is " + word);
if (diff <= 1) {
if (difference(end, word) == 1) {
availablePathCntList.add(count + 1);
} else {
count++;
find(Dictionary, new String(word), new String(end), (HashSet) used.clone(), count);
}
}
}
}
return 0;
}
private static int difference(String first, String second) {
char[] firstArr = first.toCharArray();
char[] secondArr = second.toCharArray();
int mismatch = 0;
for (int i = 0; i < firstArr.length; i++) {
if (firstArr[i] != secondArr[i]) {
mismatch++;
}
}
return mismatch;
}
}
I don’t understand why this code is posted, it has time limit exceeded issue on Leetcode.
This can definitely be better. You should include visited words and make sure you are not adding visited words back to the graph.
any c# code?
this is not working, returns 0
for the same input as yours with dictionary changed to below:
dict = [“hot”,”dot”,”dog”,”lot”,”aog”,”log”]
answer will change like : “hit” -> “hot” -> “dot” -> “dog” -> “aog”->”cog”,
but from dog to cog also we can go directly, how will you avoid that?
Solution just using 2 HashMaps and 1 ArrayList
package leetcode;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Solution {
private static int min = Integer.MAX_VALUE;
private static List visitedkeys = new ArrayList();
public void wordladder(String start, String end, String[] dict) {
//Word ladder
Map map2 = new HashMap();
Map<String, List> map = new HashMap();
int i=0;
map2.put(i++, start);
map.put(start, new ArrayList());
for (String d : dict) {
map2.put(i++, d);
map.put(d, new ArrayList());
}
map2.put(i, end);
map.put(end, new ArrayList());
int n = map2.size();
for (i=0; i < n; i++) {
for (int j=0; j < n; j++) {
if (isConvertible(map2.get(i), map2.get(j))) {
map.get(map2.get(i)).add(map2.get(j));
}
}
}
length(map, start, end, 1);
if (min != Integer.MAX_VALUE){
System.out.println(min);
}
else {
System.out.println("no path");
}
}
private boolean isConvertible(String s1, String s2) {
if (s1.length() != s2.length()) {
return false;
}
int diff = 0;
for (int i = 0; i < s1.length(); i++) {
if (s1.charAt(i) != s2.charAt(i)) {
diff += 1;
}
}
return (diff == 1) ? true : false;
}
private void length(Map<String, List> map, String key, String end, int len) {
if (key == end) {
if (len < min)
min = len;
return;
}
List lst = map.get(key);
for (String v : lst) {
if (!visitedkeys.contains(v)){
visitedkeys.add(v);
length(map, v, end, len+1);
visitedkeys.remove(visitedkeys.size()-1);
}
}
}
}
Does this solution give length of shortest transformation sequence or length of first sequence found ?
Can you please tell me the complexity for both the methods?
can you tell me what is the complexity of this method
Solution posted in the task is not correct.
Here is mine:
Test.java file:
import java.util.*;
public class Test {
public static void main(String argv[]){
String start = "hit";
String end = "cog";
String[] dict = {"cot","hot","dot","cit","dog","lot","log"};
// "hit" -> "cit" -> "cot" -> "cog"
// length = 4
int minDistance = getDistance(start, end);
List nodesToCheck = new ArrayList();
List newNodes = new ArrayList();
List winners = new ArrayList();
nodesToCheck.add(new TreeElem(start, null, minDistance, 1));
do {
for (TreeElem node : nodesToCheck) {
for (int i = 0; i 0);
if (winners.size() == 0) {
System.out.println("No solution found.");
return;
}
TreeElem winner = null;
int minLength = -1;
for (TreeElem e : winners) {
if (winner == null) {
winner = e;
minLength = e.distanceFromTop;
}
if (e.distanceFromTop = 0; i--) {
System.out.print("[" + steps[i] + "] -> ");
}
System.out.println("[" + end + "]");
}
public static int getDistance(String str1, String str2) {
int dist = 0;
for (int i = 0; i < str1.length(); i++) {
if (str1.charAt(i) != str2.charAt(i)) {
dist++;
}
}
return dist;
}
public static boolean isUsed(TreeElem node, String value) {
while (node.parent != null) {
if (node.value.equals(value)) {
return true;
}
node = node.parent;
}
return false;
}
}
TreeElem.java file:
import java.util.*;
public class TreeElem{
public String value;
public TreeElem parent;
List childs;
public int distanceToEnd;
public int distanceFromTop;
public TreeElem(String value, TreeElem parent, int distanceToEnd, int distanceFromTop) {
this.value = value;
this.parent = parent;
this.childs = new ArrayList();
this.distanceToEnd = distanceToEnd;
this.distanceFromTop = distanceFromTop;
}
public void addChild(TreeElem child) {
childs.add(child);
}
}
Without using a queue. Please let me know if you see any issues with this?
public int getCount(String start, String end, Set dict){
// Basic edge cases
if(start==null || end==null || start.length()!=end.length()) return -1;
if(dict.isEmpty()) return -1;
dict.add(end);
int count = 0;
int i = 0;
while(i<start.length()){
boolean found = false;
char[] arr = start.toCharArray();
char tmp = arr[i];
for(int j=97;j<=122;j++){
arr[i] = (char)j;
String checker = new String(arr);
if(dict.contains(checker)){
count++;
dict.remove(checker);
if(checker.equals(end)) {
return count;
}
else {
start = checker;
found = true;
i = 0;
break;
}
}
}
if(!found){
arr[i] = tmp;
i++;
}
}
return -1;
}
Can be solved by Dijkstra.
If anyone interested for both BFS and DFS approach:
http://javabypatel.blogspot.in/2015/10/word-ladder-doublets-word-links-word-golf.html
Too much code for an interview or competition problem.
Try to keep it as simple and small as possible 😉
BFS is a really good way of solving this problem
Hi
I have solved this problem using Graph of word and then run on it BFS.
package Questions;
import java.util.HashMap;
import java.util.Queue;
import java.util.HashSet;
import java.util.LinkedList;
public class WordLadder {
//solution function
public static int ladderLength(String start, String end,
HashSet dict) {
// saving the graph nodes on hash map.
HashMap nodes = new HashMap();
// adding the start and the end words to the dict
dict.add(start);
dict.add(end);
for (String word : dict) {
nodes.put(word, new GraphNode(word));
}
// update each node’s adjacents according to one character different relation
Object[] dictArray = dict.toArray();
for (int i = 0; i < dictArray.length; i++) {
for (int j = i + 1; j < dictArray.length; j++) {
if (isNeighbor((String) dictArray[i], (String) dictArray[j])) {
nodes.get((String) dictArray[i]).childs.add(nodes
.get((String) dictArray[j]));
nodes.get((String) dictArray[j]).childs.add(nodes
.get((String) dictArray[i]));
}
}
}
// Run BFS on the Graph and take the dist generated as result
HashMap result = BFS(nodes, start);
// Return the distance of the end word node from the start word node
return result.get(end);
}
// BFS function
public static HashMap BFS(
HashMap nodes, String start) {
HashMap visited = new HashMap();
HashMap dist = new HashMap();
for (String key : nodes.keySet()) {
visited.put(key, 0);
dist.put(key, 0);
}
Queue q = new LinkedList();
q.add(start);
visited.put(start, 1);
while (!q.isEmpty()) {
String dequeued = q.remove();
GraphNode curNode = nodes.get(dequeued);
LinkedList currAdjs = curNode.childs;
for (int i = 0; i < currAdjs.size(); i++) {
GraphNode adj = (GraphNode) currAdjs.get(i);
if (visited.get(adj.word) == 0) {
visited.put(adj.word, 1);
dist.put(adj.word, dist.get(dequeued) + 1);
q.add(adj.word);
}
}
}
return dist;
}
// check if two words differ by one character
public static boolean isNeighbor(String a, String b) {
assert a.length() == b.length();
int differ = 0;
for (int i = 0; i 1)
return false;
}
return true;
}
public static void main(String[] args) {
// dict = [“hot”,”dot”,”dog”,”lot”,”log”] result 5;
HashSet dict = new HashSet();
dict.add(“hot”);
dict.add(“dot”);
dict.add(“dog”);
dict.add(“lot”);
dict.add(“log”);
System.out.println(ladderLength(“hit”, “cog”, dict));
}
}
class GraphNode {
String word;
LinkedList childs;
public GraphNode(String word) {
this.word = word;
childs = new LinkedList();
}
}
I would like to have feedback on my code ?
Thanks
That’s nice idea to keep only the actual existing letters at each index.
suboptimal solutions. Better would be 1-grams.
You also don’t necessarily need two queues. You could create a WordNode class inside the method and have a word field and a distance field. Then you can create a queue of “WordNode”s. Also, I think there is no need to compare the distance to previously recorded one, since breadth search will reach the end word in the shortest path. Whenever you reach the end word, that is the shortest distance.
Thanks a ton!! You rock!! Keep it up 🙂
The problem is fixed.
Thanks! Changed. And you are welcome:)
You just need to add end to dict. Then it will be correct.
Btw, thanks a lot for ur code:)
You can create a separate list that stores words when found in the dictionary.
Yes, you are right. Surprisingly, the seoncd one can be acceptted by leetcode.
shortest path problem with dictionary extended to include start and end and weight equals to 1 if distance(a, b) == 1, else weight equals infinite
we stop at the first time we find the target word and return “length”. All the words that will be added in the stack after that will be > length as we push words in stack after length +1 .
We can add a condition that if (newword.equals(target)) return currDistance +1;
yeah second algo is wrong
Hi! I think you were oversimplifying the problem. the edge cannot be weighted just based on the number of characters in common. And an edge cannot even be determined between two words just because they have common characters. You have to factor in what are included the dictionary. One simple example, ‘good’ and ‘doom’ have two common characters and suppose the dictionary only contains ‘good’ and ‘doom’…Apparently no edge of path could be established between the two words.
Why? And how does a correct one look like?
Agree with most of the comments here:
First: the dictionary here needs to include the end word
Second: the second solution does not find the optimal shortest path, it only finds the first valid path.
I have come up with my own solution which does the following:
1. Instead of trying to iterate through all chars from a to z, it parses the dictionary and maintains a map between index and possible chars for that index in the dictionary, so flipping a character only flipped to possible dictionary words.
2. recursive Graph depth first search which keeps tracks of all sub path size and choose the shortest one.
Please kindly review and comment to help improve the algo
https://github.com/ifwonderland/leetcode/blob/master/src/main/java/leetcode/string/WordLadder.java
https://github.com/ifwonderland/leetcode/blob/master/src/main/java/leetcode/util/WordFlipperUtils.java
I think this solution is totally wrong.
I think there should be a check on the currWord and the end to stop the search in the dict:
The second solution doesn’t work. Try with input: “hit”, “lag”, [“hot”,”hog”,”dot”,”dog”,”lot”,”log”]
Example sequence: hit > hot > hog > log > lag The answer should be 5. But, it shows 0
I mean first
Priest solution is obviously wrong even if don’t consider if it’s optimally
how it will accepted?? as it will not return as cog is not inside in dict, so currWord.equals(end) will false and return 0.
The algorithm can’t guarantee find the shortest transformation sequence.
Nice!!!
How can I print the world ladder answers, after getting the distance.? Thanks for the answers.
This should be a shortest path problem: if two words has common character, they are connected by edge. The weight of the edge is the number of character in common. So the problem becomes shortest path problem.
That’s right. A sentence should be added “dict.add(end)”.
hey guess for the “a”, “c” dict = {a,b,c} example the correct ans should be 1 😉
Also, “int result = 0;” This sentence seems redundant..
The second algo has a bug. What the problem says is that “Each intermediate word must exist in the dictionary”. However, this solution assumes the last one(“cog”) also need to be in the dict, which is not necessary..